黄仁勋在GTC演讲中称推理让算力需求暴增100倍
腾讯科技特约作者 苏扬、郝博阳
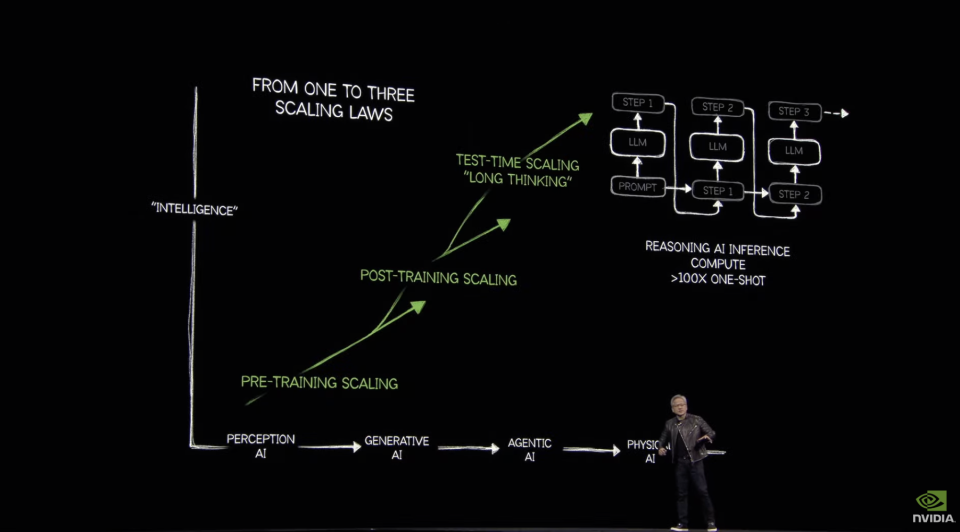
作为AI时代的“卖铲人”,黄仁勋和他的英伟达,始终坚信算力永不眠。今天的GTC大会上,黄仁勋拿出了全新的Blackwell Ultra GPU,以及在此基础上衍生的应用于推理、Agent的服务器SKU,也包括基于Blackwell架构的RTX全家桶,这一切都与算力有关,但接下来更重要的是,如何将源源不断算力,合理有效地消耗掉。在黄仁勋眼里,通往AGI需要算力,具身智能机器人需要算力,构建Omniverse与世界模型更需要源源不断的算力,至于最终人类构建一个虚拟的“平行宇宙”,需要多少算力,英伟达给了一个答案——过去的100倍。为了支撑自己的观点,黄仁勋在GTC现场晒了一组数据——2024年美国前四云厂总计采购130万颗Hopper架构芯片,到了2025年,这一数据飙升至360万颗Blackwell GPU。
以下是腾讯科技整理的英伟达GTC 2025大会的一些核心要点:Blackwell全家桶上线
1)年度“核弹”Blackwell Ultra在挤牙膏
英伟达去年GTC发布Blackwell架构,并推出GB200芯片,今年的正式名称做了微调,不叫之前传言的GB300,直接就称之为Blakwell Ultra。但从硬件来看,就是在去年基础上更换了新的HBM内存。一句话理解就是,Blackwell Ultra= Blackwell大内存版本。Blackwell Ultra由两颗台积电N4P(5nm)工艺,Blackwell 架构芯片+Grace CPU封装而来,并且搭配了更先进的12层堆叠的HBM3e内存,显存提升至为288GB,和上一代一样支持第五代NVLink,可实现1.8TB/s的片间互联带宽。

NVLink历代性能参数
基于存储的升级,Blackwell GPU的FP4精度算力可以达到15PetaFLOPS,基于Attention Acceleration机制的推理速度,比Hopper架构芯片提升2.5倍。
2)Blackwell Ultra NVL72:AI推理专用机柜

和GB200 NVL72一样,英伟达今年也推出了类似的产品Blackwell Ultra NVL72机柜,一共由18个计算托盘构成,每个计算托盘包含4颗Blackwell Ultra GPU+2颗Grace CPU,总计也就是72颗Blackwell Ultra GPU+36颗Grace CPU,显存达到20TB,总带宽576TB/s,外加9个NVLink交换机托盘(18颗NVLink 交换机芯片),节点间NVLink带宽130TB/s。机柜内置72张CX-8网卡,提供14.4TB/s带宽,Quantum-X800 InfiniBand和Spectrum-X 800G以太网卡则可以降低延迟和抖动,支持大规模AI集群。此外,机架还整合了18张用于增强多租户网络、安全性和数据加速BlueField-3 DPU。英伟达说这款产品是“为AI推理时代”专门定制,应用场景包括推理型AI、Agent以及物理AI(用于机器人、智驾训练用的数据仿真合成),相比前一代产品GB200 NVL72的AI性能提升了1.5倍,而相比Hopper架构同定位的DGX机柜产品,可以为数据中心提供50倍增收的机会。根据官方提供的信息,6710亿参数DeepSeek-R1的推理,基于H100产品可实现每秒100tokens,而采用Blackwell Ultra NVL72方案,可以达到每秒1000 tokens。换算成时间,同样的推理任务,H100需要跑1.5分钟,而Blackwell Ultra NVL72 15秒即可跑完。
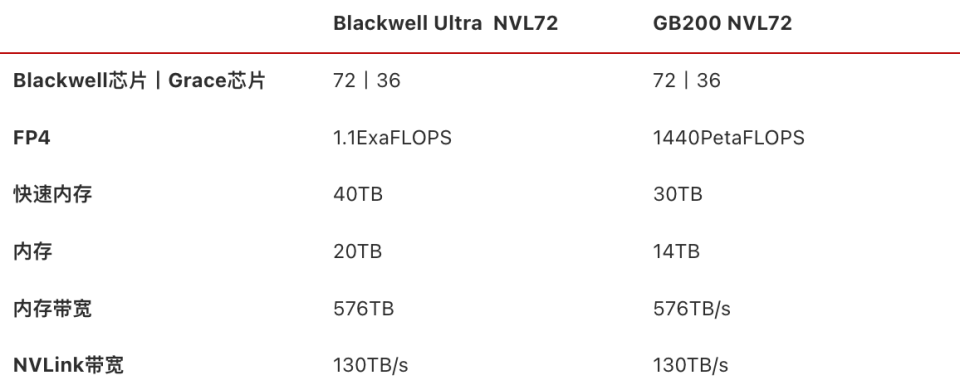
Blackwell Ultra NVL72和GB200 NVL72硬件参数根据英伟达提供的信息,Blackwell NVL72相关产品预计在2025年下半年上市,客户包括服务器厂商、云厂、算力租赁服务商几大类:
- Cisco/Dell/HPE/Lenovo/超微等15家制造商
- AWS/Google Cloud/Azure/Oracle云等主流平台
3)提前预告真“核弹”GPU Rubin芯片
按照英伟达的路线图,GTC2025的主场就是Blackwell Ultra。不过,黄仁勋也借这个场子预告了2026年上市的基于Rubin架构的下一代GPU以及更强的机柜Vera Rubin NVL144——72颗Vera CPU+144颗 Rubin GPU,采用288GB显存的HBM4芯片,显存带宽13TB/s,搭配第六代NVLink和CX9网卡。这个产品有多强呢?FP4精度的推理算力达到了3.6ExaFLOPS,FP8精度的训练算力也达到了1.2ExaFlOPS,性能是Blackwell Ultra NVL72的3.3倍。如果你觉得还不够,没关系,2027年还有更强的 Rubin Ultra NVL576机柜,FP4精度的推理和FP8精度的训练算力分别是15ExaFLOPS和5ExaFLOPS,14倍于Blackwell Ultra NVL72。

英伟达官方提供的Rubin Ultra NVL144和Rubin Ultra NVL576参数
4)Blackwell Ultra版DGX Super POD“超算工厂“
对于那些现阶段Blackwell Ultra NVL72都不能满足需求,又不需要搭建超大规模AI集群的客户,英伟达的解决方案是基于Blackwell Ultra、即插即用的DGX Super POD AI超算工厂。作为一个即插即用的AI超算工厂,DGX Super POD主要面向专为生成式AI、AI Agent和物理模拟等AI场景,覆盖从预训练、后训练到生产环境的全流程算力扩展需求,Equinix作为首个服务商,提供液冷/风冷基础架构支持。由Blackwell Ultra构建的DGX SuperPod基于Blackwell Ultra定制的DGX Super POD分两个版本:
- 内置DGX GB300(Grace CPU ×1+Blackwell Ultra GPU ×2) 的DGX SuperPOD,总计288颗Grace CPU+576颗 Blackwell Ultra GPU,提供300TB的快速内存,FP4精度下算力为11.5ExaFLOPS
- 内置DGX B300的DGX SuperPOD,这个版本不含Grace CPU芯片,具备进一步的扩展空间,且采用的是风冷系统,主要应用场景为普通的企业级数据中心
5)DGX Spark与DGX Station
今年1月份,英伟达在CES上晒了一款售价3000美元的概念性的AI PC产品——Project DIGITS,现在它有了正式名称DGX Spark。产品参数方面,搭载GB10芯片,FP4精度下算力可以达到1PetaFlops,内置128GB LPDDR5X 内存,CX-7网卡,4TB NVMe存储,运行基于Linux定制的DGX OS操作系统,支持Pytorch等框架,且预装了英伟达提供的一些基础AI软件开发工具,可以运行2000亿参数模型。整机的尺寸和Mac mini的大小接近,两台DGX Spark互联,还可以运行超过4000亿参数的模型。虽然我们说它是AI PC,但本质上仍然属于超算范畴,所以被放在了DGX产品系列当中,而不是RTX这样的消费级产品里面。不过也有人吐槽这款产品,FP4的宣传性能可用性低,换算到FP16精度下只能跟RTX 5070,甚至是250美元的Arc B580对标,因此性价比极低。

DGX Spark计算机与DGX Station工作站除了拥有正式名称的DGX Spark,英伟达还推出了一款基于Blackwell Ultra的AI工作站,这个工作站内置一颗Grace CPU和一颗Blackwell Ultra GPU,搭配784GB的统一内存、CX-8网卡,提供20PetaFlops的AI算力(官方未标记,理论上也是FP4精度)。
6)RTX横扫AI PC,还要挤进数据中心
前面介绍的都是基于Grace CPU和Blackwell Ultra GPU的产品SKU,且都是企业级产品,考虑到很多人对RTX 4090这类产品在AI推理上的妙用,英伟达本次GTC也进一步强化了Blackwell和RTX系列的整合,推出了一大波内置GDDR7内存的AI PC相关GPU,覆盖笔记本、桌面甚至是数据中心等场景。
- 桌面GPU:,包括RTX PRO 6000 Blackwell 工作站版、RTX PRO 6000 Blackwell Max-Q工作站版、RTX PRO 5000 Blackwell、RTX PRO 4500 Blackwell 以及RTX PRO 4000 Blackwell
- 笔记本GPU:RTX PRO 5000 Blackwell、RTX PRO 4000 Blackwell、RTX、PRO 3000 Blackwell、RTX PRO 2000 Blackwell、RTX PRO 1000 Blackwell以及RTX PRO 500 Blackwell
- 数据中心 GPU:NVIDIA RTX PRO 6000 Blackwell服务器版

以上还只是部分基于Blackwell Ultra芯片针对不同场景定制的SKU,小到工作站,大到数据中心集群,英伟达自己将其称之为“Blackwell Family”(Blackwell家族),中文翻译过来“Blackwell全家桶”再合适不过。
英伟达Photonics
站在队友肩膀上的CPO系统
光电共封模块(CPO)的概念,简单来说就是将交换机芯片和光学模块共同封装,可实现光信号转化为电信号,充分利用光信号的传输性能。在此之前,业界就一直在讨论英伟达的CPO网络交换机产品,但一直迟迟未上线,黄仁勋在现场也给了解释——由于在数据中心中大量使用光纤连接,光学网络的功耗相当于计算资源的10%,光连接的成本直接影响着计算节点的Scale-Out网络和AI性能密度提升。

GTC上展示的两款硅光共封芯片Quantum-X、Spectrum-X参数今年的GTC英伟达一次性推出了Quantum-X硅光共封芯片、Spectrum-X硅光共封芯片以及衍生出来的三款交换机产品:Quantum 3450-LD、Spectrum SN6810和Spectrum SN6800。
- Quantum 3450-LD:144个800GB/s端口,背板带宽115TB/s,液冷
- Spectrum SN6810:128个800GB/s端口,背板带宽102.4TB/s,液冷
- Spectrum SN6800:512个800GB/s端口,背板带宽409.6TB/s,液冷
上述产品统一归类到“NVIDIA Photonics”,英伟达说这是一个基于CPO合作伙伴生态共创研发的平台,例如其搭载的微环调制器(MRM)是基于台积电的光引擎优化而来,支持高功率、高能效激光调制,并且采用可拆卸光纤连接器。比较有意思的是,根据之前业内的资料,台积电的微环调制器(MRM)是其与博通基于3nm工艺以及CoWoS等先进封装技术打造而来。按照英伟达给的数据,整合光模块的Photonics交换机相比传统交换机,性能提升3.5倍,部署效率也可以提升1.3倍,以及10倍以上的扩展弹性。
模型效率PK DeepSeek
软件生态发力AI Agent
因为本次长达2个小时的GTC上,黄仁勋总共只讲大概半个小时软件和具身智能。因此很多细节都是通过官方文档进行补充的,而非完全来自现场。
1)Nvidia Dynamo,英伟达在推理领域构建的新CUDA
Nvidia Dynamo绝对是本场发布的软件王炸。它是一个专为推理、训练和跨整个数据中心加速而构建的开源软件。Dynamo的性能数据相当震撼:在现有Hopper架构上,Dynamo可让标准Llama模型性能翻倍。而对于DeepSeek等专门的推理模型,NVIDIA Dynamo的智能推理优化还能将每个GPU生成的token数量提升30倍以上。
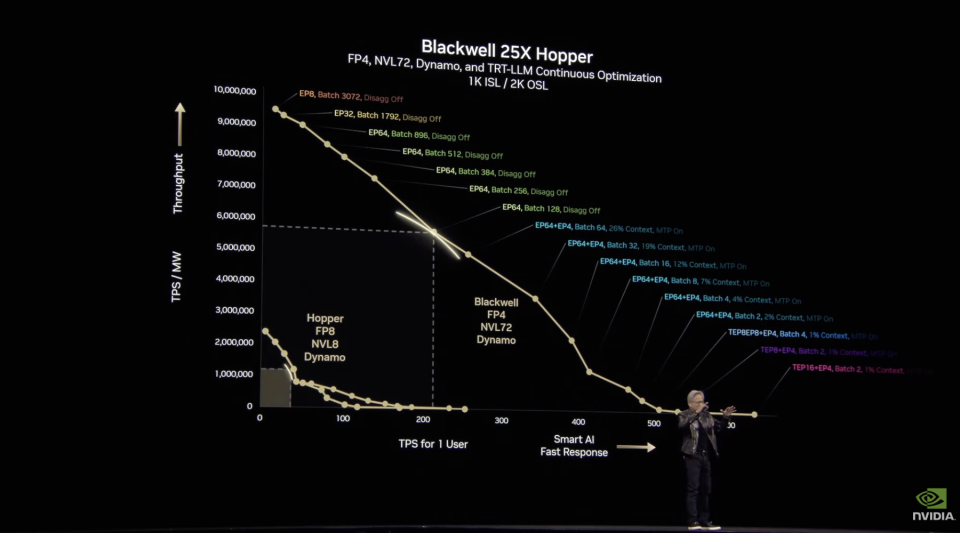
黄仁勋演示加了Dynamo的Blackwell能超过25倍的HopperDynamo的这些改进主要得益于分布化。它将LLM的不同计算阶段(理解用户查询和生成最佳响应)分配到不同GPU,使每个阶段都能独立优化,提高吞吐量并加快响应速度。
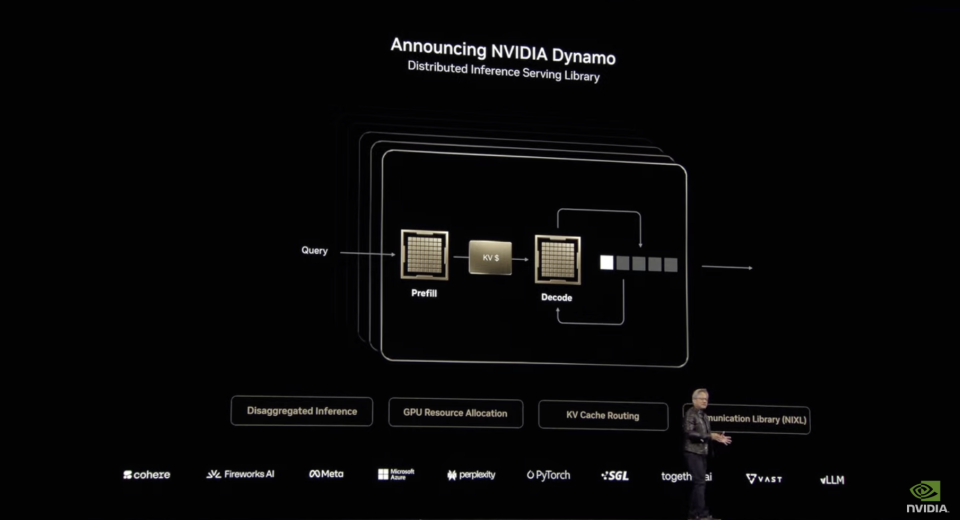
比如在输入处理阶段,也就是预填充阶段,Dynamo能够高效地分配GPU资源来处理用户输入。系统会利用多组GPU并行处理用户查询,希望GPU处理的更分散、更快。Dynamo用FP4模式调用多个GPU同时并行“阅读”和“理解”用户的问题,其中一组GPU处理“第二次世界大战”的背景知识、另一组处理“起因“相关的历史资料、第三组处理“经过“的时间线和事件,这一阶段像是多个研究助理同时查阅大量资料。而在生成输出tokens,也就是解码阶段,则需要让GPU更专注和连贯。比起GPU数量,这个阶段更需要更大的带宽去吸取前一阶段的思考信息,因此也需要更多的缓存读取。Dynamo优化了GPU间通信和资源分配,确保连贯且高效的响应生成。它一方面充分利用了NVL72架构的高带宽NVLink通信能力,最大化令牌生成效率。另一方面通过“Smart Router”将请求定向到已缓存相关KV(键值)的GPU上,这可以避免重复计算,极大地提高了处理速度。由于避免了重复计算,一些GPU资源被释放出来Dynamo可以将这些空闲资源动态分配给新的传入请求。这一套架构和Kimi的Mooncake架构非常类似,但在底层infra上英伟达做了更多支持。Mooncake大概可以提升5倍左右,但Dynamo在推理上提升的更明显。比如Dynamo的几项重要创新中,“GPU Planner”能够根据负载动态调整GPU分配,“低延迟通信库”优化了GPU间数据传输,而“内存管理器”则智能地将推理数据在不同成本级别的存储设备间移动,进一步降低运营成本。而智能路由器,LLM感知型路由系统,将请求定向到最合适的GPU,减少重复计算。这一系列能力都使得GPU的负载达到最佳化。利用这一套软件推理系统能够高效扩展到大型GPU集群,最高可以使单个AI查询无缝扩展到多达1000个GPU,以充分利用数据中心资源。而对于GPU运营商来讲,这个改进使得每百万令牌成本显著下降,而产能大幅提升。同时单用户每秒获得更多token,响应更快,用户体验改善。
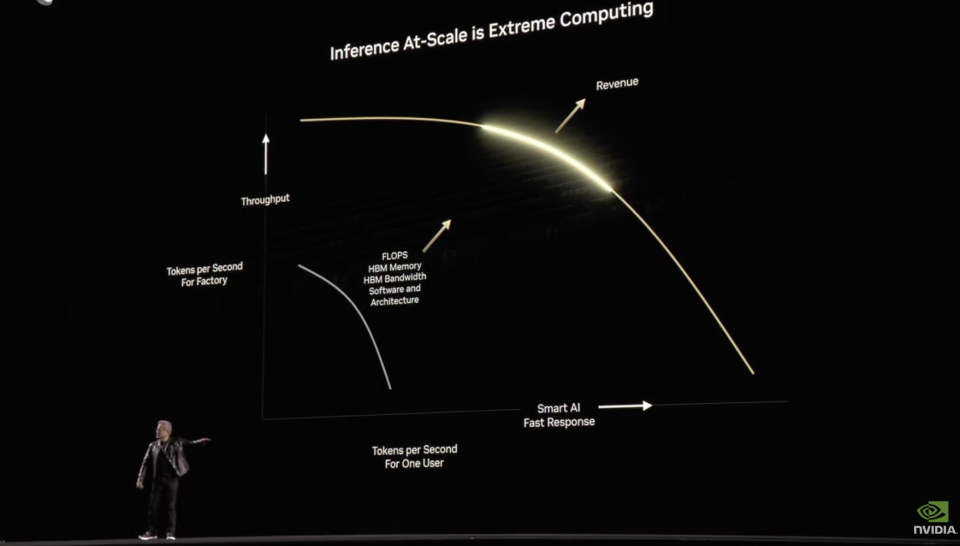
用Dynamo,让服务器达到吞吐量和应答速度间的黄金收益线与CUDA作为GPU编程的底层基础不同,Dynamo是一个更高层次的系统,专注于大规模推理负载的智能分配和管理。它负责推理优化的分布式调度层,位于应用程序和底层计算基础设施之间。但就像CUDA十多年前彻底改变了GPU计算格局,Dynamo也可能成功开创推理软硬件效率的新范式。Dynamo完全开源,支持从PyTorch到Tensor RT的所有主流框架。开源了也照样是护城河。和CUDA一样,它只对英伟达的GPU有效果,是NVIDIA AI推理软件堆栈的一部分。用这个软件升级,NVIDIA构筑了自己反击Groq等专用推理AISC芯片的城防。必须软硬搭配,才能主导推理基础设施。
2)Llama Nemotron新模型秀高效,但还是打不过DeepSeek
虽然在服务器利用方面,Dynamo 确实相当惊艳,但在训练模型方面英伟达还和真内行有点差距。英伟达在这次GTC上用一款新模型Llama Nemotron,主打高效、准确。它是由Llama系列模型衍生而来。经过英伟达特别微调,相较于Llama本体,这款模型经过算法修剪优化,更加轻量级,仅有48B。它还具有了类似o1的推理能力。与Claude 3.7和Grok 3一样,Llama Nemotron模型内置了推理能力开关,用户可选择是否开启。这个系列分为三档:入门级的Nano、中端的Super和旗舰Ultra,每一款都针对不同规模的企业需求。
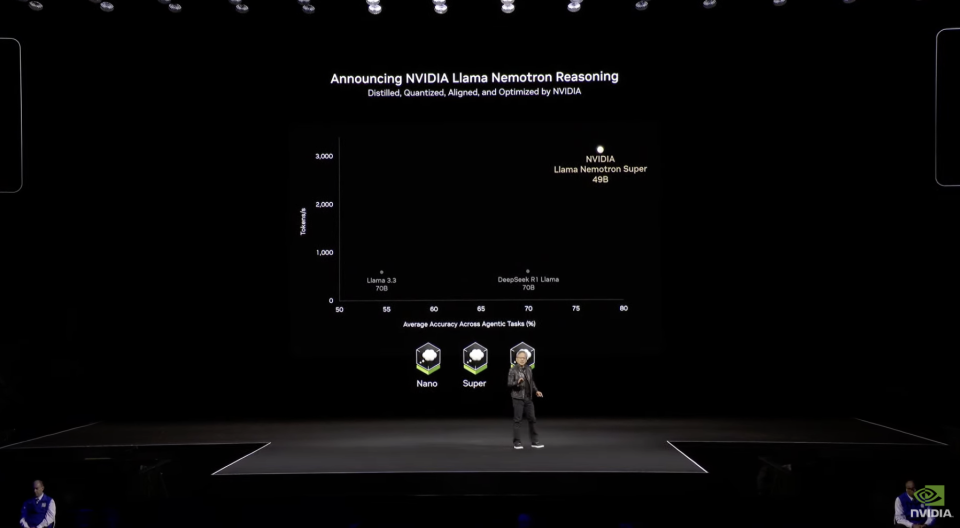
说到高效,这一模型的微调数据集完全英伟达自己生成的合成数据组成,总数约60B token。相比DeepSeek V3用130万H100小时完整训练,这个仅有DeepSeek V3 1/15参数量的模型只是微调就用了36万H100小时。训练效率比DeepSeek差一个等级。在推理上效率上,Llama Nemotron Super 49B模型确实比上一代模型表现要好得多,其token吞吐量能达到Llama 3 70B 的5倍,在单个数据中心GPU下它可以每秒吞吐3000 token以上。但在DeepSeek 开源日最后一天公布的数据中,每个H800 节点在预填充期间平均吞吐量约为73.7k tokens/s 输入(包括缓存命中)或在解码期间约为14.8k tokens/s 输出。两者差距还是很明显的。从性能上看,49B的Llama Nemotron Super 在各项指标中都超过了70B的经DeepSeek R1蒸馏过的Llama 70B模型。不过考虑到最近Qwen QwQ 32B模型之类的小参数高能模型频繁发布,Llama Nemotron Super 估计在这些能和R1本体掰手腕的模型里难以出彩。最要命的是,这个模型,等于实锤了DeepSeek也许比英伟达更懂在训练过程中调教GPU。
3)新模型只是英伟达AI Agent生态的前菜,NVIDA AIQ才是正餐
英伟达为什么要开发一个推理模型呢?这主要是为了老黄看中的AI下一个爆点——AI Agent做准备。自从OpenAI、Claude等大厂逐步通过DeepReasearch、MCP建立起了Agent的基础后,英伟达明显也认为Agent时代到来了。NVIDA AIQ项目就是英伟达的尝试。它直接提供了一个以Llama Nemotron推理模型为核心的规划者的AI Agent现成工作流。这一项目归属于英伟达的Blueprint(蓝图)层级,它是指一套预配置的参考工作流、是一个个模版模板,帮助开发者更容易地整合NVIDIA的技术和库。而AIQ就是英伟达提供的Agent模版。
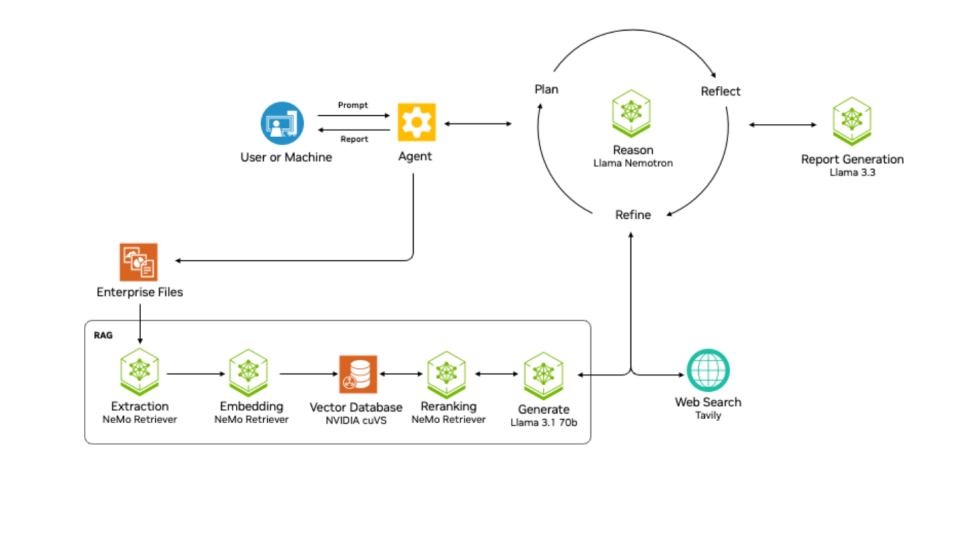
和Manus一样,它集成网络搜索引擎及其他专业AI代理等外部工具,这让这个Agent本身可以既能搜索,又能使用各种工具。通过Llama Nemotron推理模型的规划,反思和优化处理方案,去完成用户的任务。除此之外,它还支持多Agent的工作流架构搭建。
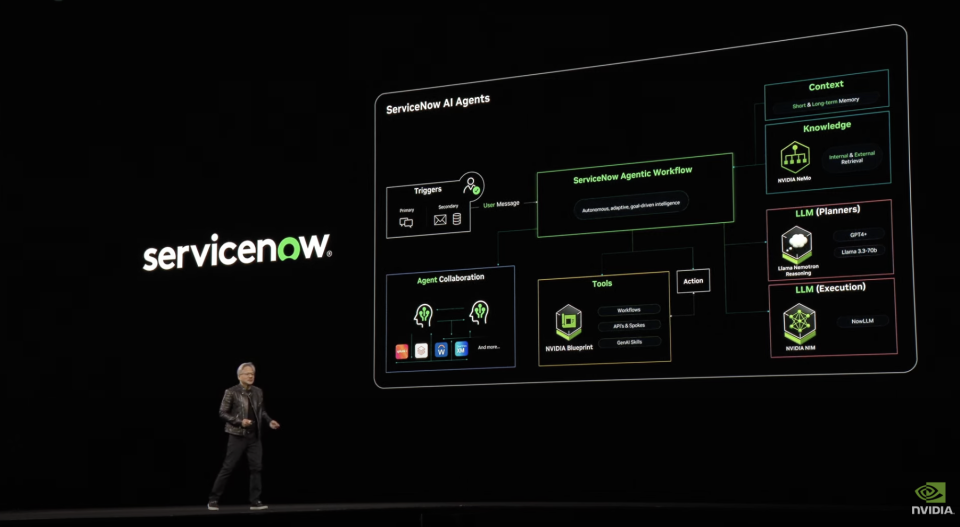
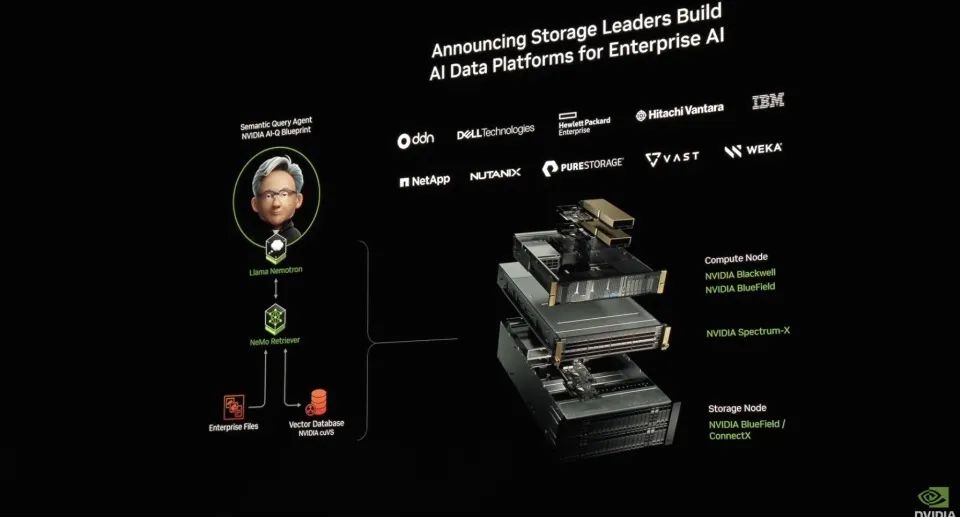
比Manus更进一步的是,它具有一个复杂的针对企业文件的RAG系统。这一系统包括提取、嵌入、向量存储、重排到最终通过LLM处理的一系列步骤,能保证企业数据为Agent所用。在此之上,英伟达还推出了AI数据平台,把AI推理模型接到企业数据的系统上,形成一个针对企业数据的DeepReasearch。使得存储技术的重大演进,使得存储系统不再仅是数据的仓库,而是拥有主动推理和分析能力的智能平台。
另外,AIQ非常强调可观察性和透明度机制。这对于安全和后续改进来讲非常重要。开发团队能够实时监控Agent的活动,并基于性能数据持续优化系统。整体来讲NVIDA AIQ是个标准的Agent工作流模版,提供了各种Agent能力。算是进化到推理时代的,更傻瓜的Dify类Agent构筑软件。
人形机器人基础模型发布
英伟达要做具身生态全闭环
1)Cosmos,让具身智能理解世界
如果说专注Agent还是投注现在,那英伟达在具身智能上的布局完全算得上是整合未来了。先从模型开始说,本次GTC放出了今年1月公布的具身智能基础模型Cosmos的升级版。Cosmos是一个能通过现在画面,去预测未来画面的模型。它可以从文本/图像输入数据,生成详细的视频,并通过将其的当前状态(图像/视频)与动作(提示/控制信号)相结合来预测场景的演变。因为这需要对世界的物理因果规律有理解,所以英伟达称Cosmos是世界基础模型(WFM)。
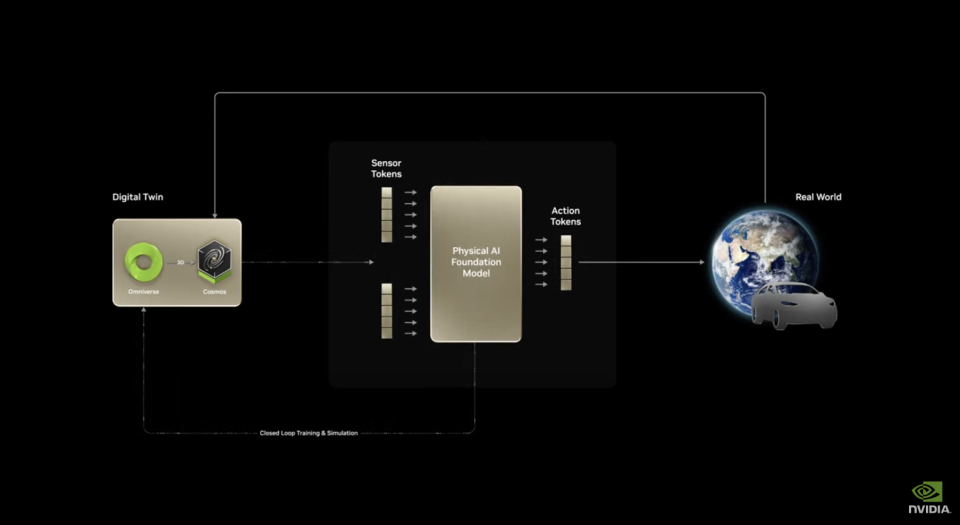
而对于具身智能而言,预测机器的行为会给外部世界带来什么影响是最核心的能力。只有这样,模型才能去根据预测规划行为,所以世界模型就成了具身智能的基础模型。有了这个基础的行为/时间-物理世界改变的世界预测模型,通过具体的如自动驾驶、机器人任务的数据集微调,这个模型就可以满足各种具有物理形态的具身智能的实际落地需要了。整个模型包含三部分能力,第一部分Cosmos Transfer 将结构化的视频文字输入转换为可控的真实感视频输出,凭空用文字产生大规模合成数据。这解决了当前具身智能最大的瓶颈——数据不足问题。而且这种生成是一种“可控”生成,这意味着用户可以指定特定参数(如天气条件、物体属性等),模型会相应调整生成结果,使数据生成过程更加可控和有针对性。整个流程还可以由Ominiverse和Cosmos结合。
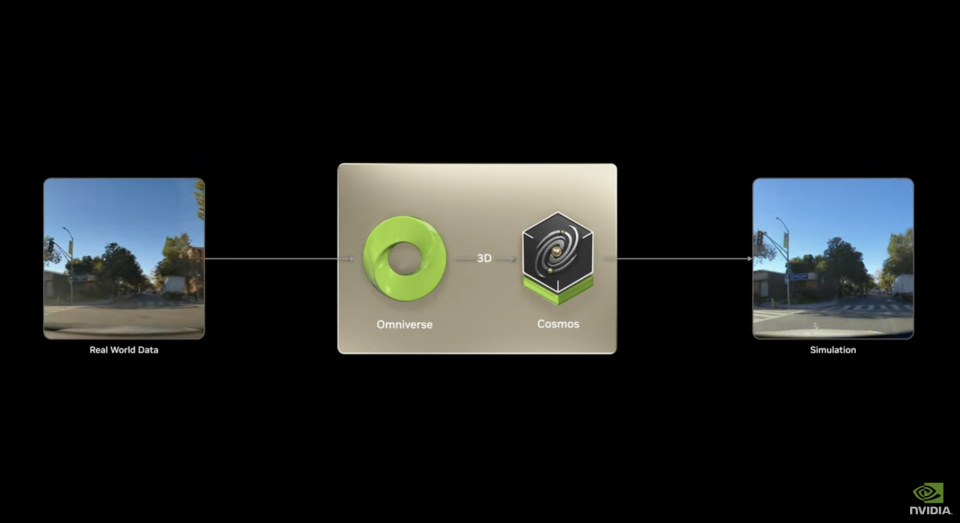
Cosmos建立在Ominiverse上的现实模拟第二部分Cosmos Predict 能够从多模态输入生成虚拟世界状态,支持多帧生成和动作轨迹预测。这意味着,给定起始和结束状态,模型可以生成合理的中间过程。这是核心物理世界认知和构建能力。第三部分是Cosmos Reason,它是个开放且可完全定制的模型,具有时空感知能力,通过思维链推理理解视频数据并预测交互结果。这是规划行为和预测行为结果的提升能力。有了这三部分能力逐步叠加,Cosmos就可以做到从现实图像token+文字命令提示token输入到机器动作token输出的完整行为链路。这一基础模型应该确实效果不俗。推出仅两个月,1X、Agility Robotics、Figure AI这三家头部公司都开始用起来了。大语言模型没领先,但具身智能英伟达确实在第一梯队里。
2)Isaac GR00T N1,世界第一个人形机器人基础模型
有了Cosmos,英伟达自然而然用这套框架微调训练了专用于人型机器人的基础模型Isaac GR00T N1。
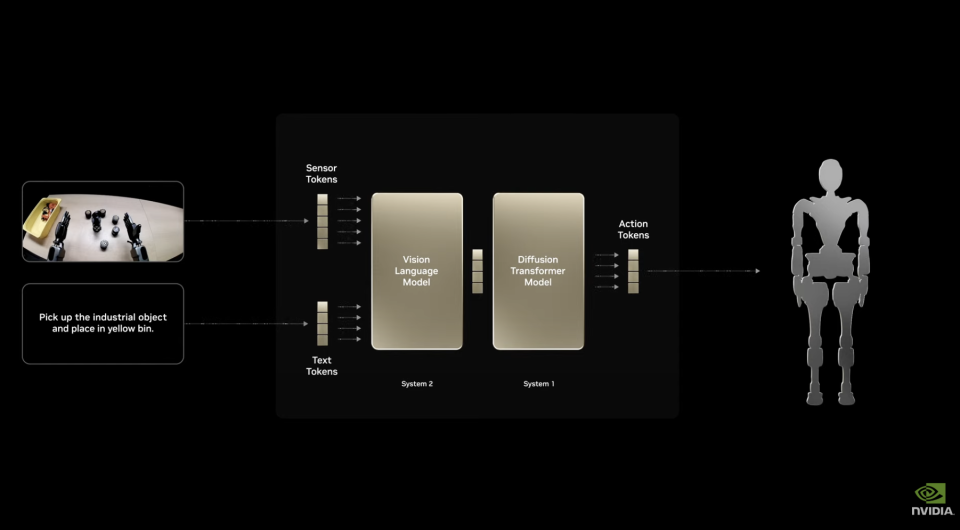
它采用双系统架构,有快速反应的“系统1“和深度推理的“系统2“。它的全面微调,使得其能处理抓取、移动、双臂操作等通用任务。而且可以根据具体机器人进行完全定制,机器人开发者可用真实或合成数据进行后训练。这使得这一模型实际上可以被部署在各种各样形状各异的机器人中。比如说英伟达与Google DeepMind和迪士尼合作开发Newton物理引擎,就用了Isaac GR00T N1作为底座驱动了一个非常不常见的小迪士尼BDX机器人。可见其通用性之强。Newton作为物理引擎非常细腻,因此足够建立物理奖励系统,以在虚拟环境中训练具身智能。

4)数据生成,双管齐下
英伟达结合NVIDIA Omniverse和上面提到的NVIDIA Cosmos Transfer世界基础模型,做出了Isaac GR00T Blueprint。它能从少量人类演示中生成大量合成动作数据,用于机器人操作训练。NVIDIA使用Blueprint的首批组件,在仅11小时内生成了78万个合成轨迹,相当于6,500小时(约9个月)的人类演示数据。Isaac GR00T N1的相当一部分数据就来自于此,这些数据使得GR00T N1的性能比仅使用真实数据提高了40%。
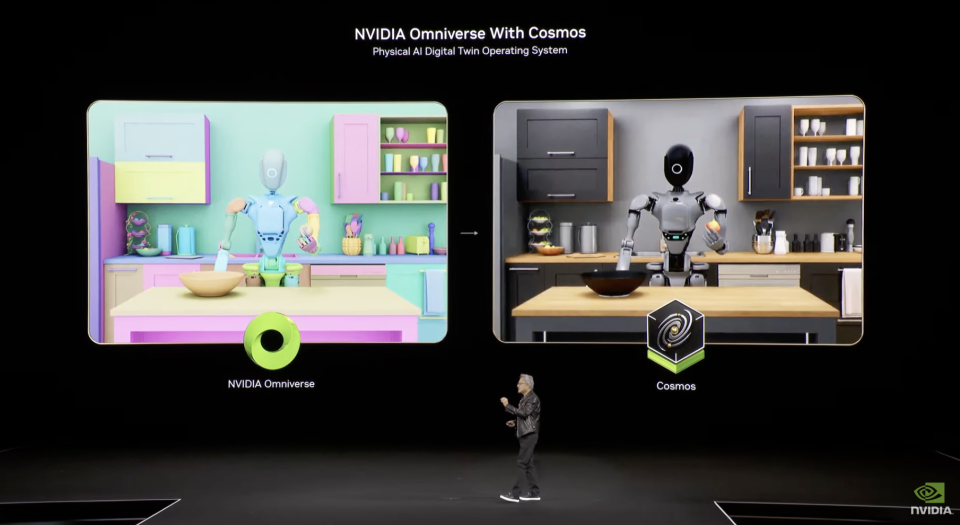
针对每个模型,靠着Omniverse这套纯虚拟系统,以及Cosmos Transfer这套真实世界图像生成系统,英伟达都能提供大量的高质量数据。这模型的第二个方面,英伟达也覆盖了。
3)三位一体算力体系,打造从训练到端的机器人计算帝国
从去年开始,老黄就在GTC上强调一个「三台计算机」的概念:一台是DGX,就是大型GPU的服务器,它用来训练AI,包括具身智能。另一台AGX,是NVIDIA为边缘计算和自主系统设计的嵌入式计算平台,它用来具体在端侧部署AI,比如作为自动驾驶或机器人的核心芯片。第三台就是数据生成计算机Omniverse+Cosmos。
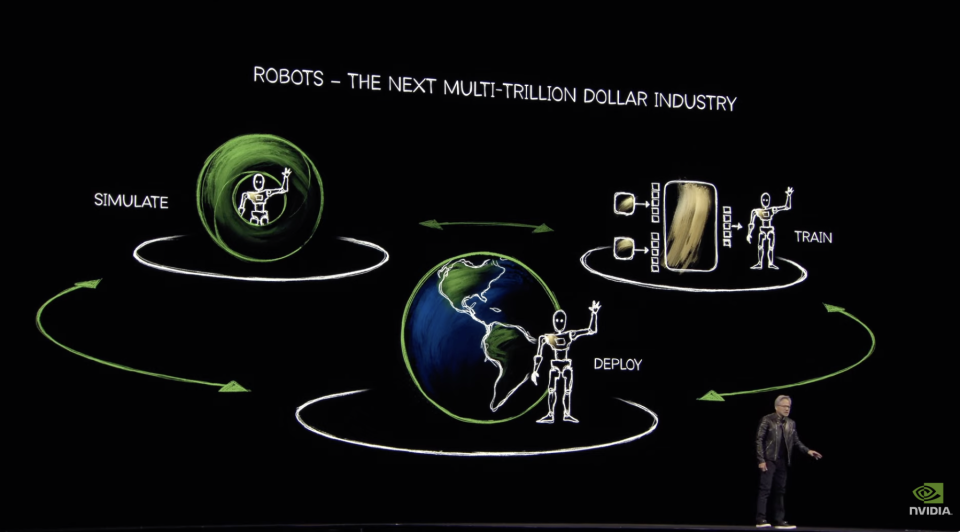
这套体系在本次GTC中又被老黄重提,且特别提到靠着这套算力系统,能诞生十亿级的机器人。从训练到部署,算力都用英伟达。这一部分也闭环了。

结语
如果单纯对比上一代Blackwell芯片,Blackwell Ultra在硬件上确实匹配不上之前的“核弹”、“王炸”这些形容词,甚至有些挤牙膏的味道。但如果从路线图规划的角度来看,这些又都在黄仁勋的布局之中,明年、后年的Rubin架构,从芯片工艺,到晶体管,再到机架的集成度,GPU互联和机柜互联等规格都会有大幅度提升,用中国人习惯说的叫“好戏还在后头”。对比硬件层面上的画饼充饥,这两年英伟达在软件层面上可以说是狂飙突进。纵观英伟达的整个软件生态,Meno、Nim、Blueprint三个层级的服务把模型优化、模型封装到应用构建的全栈解决方案都包括进去了。云服务公司的生态位英伟达AI全部重合。加上这次新增的Agent,AI infra这块饼,英伟达是除了基础模型这一块之外,所有部分都要吃进去。而在机器人市场,英伟达的野心更大。模型,数据,算力三要素都抓在手里。没赶上基础语言模型的头把交椅,基础具身智能补齐。影影绰绰,一个具身智能版的垄断巨头已经在地平线上露头了。这里面,每个环节,每个产品都对应着一个潜在的千亿级市场。早年孤注一掷的好运赌王黄仁勋,靠着GPU垄断得来的钱,开始做一场更大的赌局。如果这场赌局里,软件或者机器人市场任意一方面通吃,那英伟达就是AI时代的谷歌,食物链上的顶级垄断者。不过看看英伟达GPU的利润率,我们还是期待这样的未来别来了。还好,这对于老黄这辈子来讲,也是他从没操盘过的大赌局,胜负难料。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}